









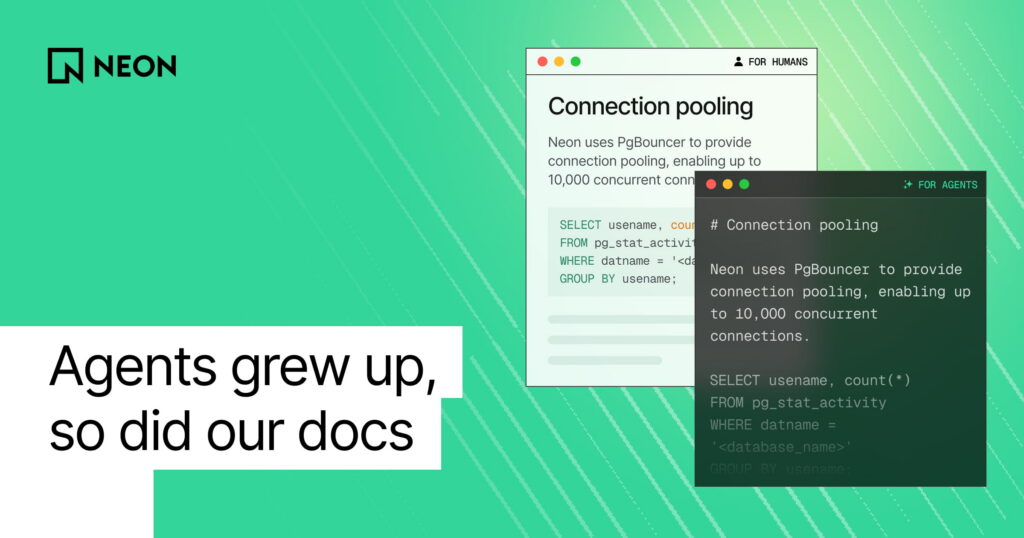
A year ago, if you asked an agent about Neon, you got whatever it half-remembered from training. Now it goes looking and reads what it finds. Our docs were written for humans who scroll, not machines that fetch.
We’ve been fixing this in pieces, not all at once. This post is what worked, what didn’t, and what we’re still figuring out. Maybe it saves you a few curl commands.
The setup
Agents can read HTML fine. Crawlers have been at it for decades and modern agents handle it well. We just think we can do better. Our pages are built from dozens of rendered React components (<Admonition>, <CodeTabs>, <DetailIconCards>, <Steps>), which expand into nested <div>s, class names, and event handlers in the final HTML. The actual docs are buried in there somewhere.
You might think: just serve your source MDX from GitHub. We once did, and it works. MDX is Markdown with React components mixed in. Our MDX uses 30+ custom ones, and some, like <SharedContent>, inline text from separate files at render time. An agent reading the raw MDX just sees the tag.
You will correctly say: convert them. We do now, after plenty of yak shaving.

Phase 1: hand-maintained text files
Our first approach: ask Claude for “one of them cool llms.txt things that all the kids are talking about.” It produced a public/llms/ directory, one .txt file per doc page, and an enormous llms.txt index listing them all. Keeping them current was a handful of Python scripts, run by hand, no CI.
It worked. The thinking at the time was “feed the models” not “serve the agents” (the spec itself leans that way). Live fetching was new and rare. Predictably, the files drifted from the source, went missing, went stale weeks at a time. The implementation was an afterthought because the use case still felt like one.
The lesson: if keeping two copies in sync is a manual job, they will drift. Clearer now than it was at the time.
Phase 2: teach the site to recognize agents
What if the site detected agent requests and served something cleaner than HTML? We built middleware that checks the User-Agent (ChatGPT, Claude, Cursor, Copilot, and others) and the Accept header. When either matches, we serve Markdown instead.
What we actually served was raw MDX from GitHub’s API with a text/markdown content type. Technically Markdown-ish, practically Markdown with a pile of React components. We hit GitHub rate limits within hours, switched to pre-built local files, still MDX. Detection was solved, content was not.
Phase 3: converting MDX to Markdown
I (okay, Claude) wrote a Node.js post-build script that converts MDX to Markdown and writes it to public/md/, which we serve via URL rewrites.
For example, <CodeTabs labels={["Node.js", "Python"]}> becomes labeled code blocks. <SharedContent> tags inline the referenced text directly. About 30 components handled, all from one file.
The processor builds ~1,400 files in a few seconds. Doc authors edit MDX as usual. No manual sync, no drift, no thought.
Context matters too
Clean Markdown isn’t enough. Agents need to know where they are and what to read next. So we wrap each page with a breadcrumb at the top and related docs at the bottom:
> This page location: Connect to Neon > Connection pooling
> Full Neon documentation index: https://neon.com/docs/llms.txt
...
## Related docs (Connect to Neon)
- [Connect to Neon](https://neon.com/docs/connect/connect-intro)
- [Choosing your connection method](https://neon.com/docs/connect/choose-connection)
...Without it, an agent fetches one page and doesn’t know what else is nearby.
What other sites are doing
Nikita (Neon’s fearless leader) has a habit of pointing people back to first principles. It’s why we tend to build small tools instead of guessing, even when the tool’s whole point is to see how others are doing it. Ours, a scanner, probes doc sites and measures how they serve content to agents: same URL as HTML, with .md appended, Accept: text/markdown, discovery headers, plus variations. Findings across over 250 sites, mostly tech docs such as Vercel, Stripe, Mintlify, Sentry, and Google:
- 53% serve Markdown by appending
.mdto the URL. - 41% honor content negotiation via
Accept: text/markdown. The ones that do also tend to havellms.txt, discovery headers, and structured indexes. They’ve thought about agents. About 30% also accepttext/plain. llms.txtis common but placement varies. 93% of polled sites have one, and 58% also publishllms-full.txtwith concatenated doc content. The standard says place llms.txt in root. In practice, sites put it at/docs/llms.txt, at the root, or both. Some have different content at each path, and some use sub-indexes (childllms.txtfiles withinllms.txt).- 404 handling is mostly not content-type aware. Only 9% return Markdown for a 404 when Markdown was requested. The rest return HTML, and a handful return empty responses, even when the agent clearly asked for Markdown via
.mdorAccept: text/markdown. Of those 9%, most sites return 200 instead of 404 (we chose 404). - Discovery hints are rarely used, and the conventions aren’t settled. Only 9% include a
<link rel="alternate" type="text/markdown">tag in the HTML head, a convention that emerged organically (ours did). TheX-LLMs-TxtandLink: rel="llms-txt"headers Mintlify proposed have adoption almost entirely driven by Mintlify itself. - Headers are mixed and the impact is unclear. Only 3% set
Vary: Accepton HTML (6% on Markdown). 27% setnoindexon Markdown. We’re still figuring out which of these actually help versus which are habit.
Doc-specific platforms like Mintlify, GitBook, and Fern score near 100% on most of these, because agent readiness is the point. Open-source frameworks are further behind and could use agent advocates. Tooling exists in the community but often sits unmaintained.
A few more lessons
404s should be helpful and aware, not empty. Our 404s match the request: HTML for browsers, Markdown for agents, the latter returning links to the full index, the complete docs bundle, and the API reference. Idea stolen from a Vercel tweet and implemented immediately.
Discovery has to be automatic, and responding to agents has to be too. Agents don’t know to look for llms.txt or that appending .md works. Set discovery headers on every HTML response so they find out, and honor Accept: text/markdown when they do ask. Like children, they often ignore the reminders, but we do our best as parents.
The index needs structure, not just a list. Our first llms.txt was a flat list of over 1,000 URLs. Way too much to parse before deciding what to read. We now restructure it with sections and descriptions, sub-indexes for large areas, a “Common Queries” section at the top (pricing, connection methods and troubleshooting, API reference), and collapsed routes for large but useful content (changelog, Postgres tutorials). The primary index is now ~200 entries with sub-indexes for the rest.
Agents use HTTP clients, not browsers. Looking at User-Agent strings, we saw axios, got, node-fetch as often as named agents. Claude Code uses axios, Cursor uses got. The agent identity is in the tool, not always the header. We added those patterns to the detection list. A false positive (Markdown to a human) is harmless; a false negative (HTML to an agent) defeats the purpose. A real question: is changing content based on who’s asking a form of cloaking?
What the system looks like now
Four layers:
- Build time. The MDX processor converts source docs to Markdown. The index generator builds
llms.txt, sub-indexes, andllms-full.txt(all docs concatenated). - URL rewrites. Appending
.mdto any doc URL serves its Markdown version frompublic/md/. Non-doc pages will follow. - Middleware. Detects agents via User-Agent and
Acceptheaders. Serves Markdown transparently. Adds discovery headers to HTML responses. - Content. Every doc page gets navigation context. The index is hierarchical. 404s are helpful and content-type aware.
What we’d do differently
One URL, two ways to ask for Markdown. We built a parallel /llms/ namespace first. Eventually we moved to serving Markdown from the canonical URL via a .md suffix or an Accept: text/markdown header. That should have been the starting point.
Invest in analytics earlier. We added agent traffic tracking late. Having it from the start would have shown which pages agents request, which ones they 404 on, and how they navigate. That data would have shaped our system sooner.
Design the index first. The flat file list was an afterthought. Structuring it with sections, descriptions, and sub-indexes earlier would have made it more useful.
Build the scanner first. Studying other sites first would have saved us from reinventing patterns and surfaced cracks we didn’t think of until later.
None of this was planned from the start. It came together one small change at a time.
What’s next
Humans reach docs through agents, not just browsers. That’s the new audience and it doesn’t execute JavaScript or follow visual navigation. Agents want plain text, structured metadata, and machine-readable discovery. The tools aren’t exotic: a remark pipeline, some middleware, a few HTTP headers, a config file. The hard part is recognizing that and choosing to serve them.
An agent can implement most of this for you. What it can’t do is write good content without review.
Community tooling is catching up. The afdocs scorecard flagged a coverage issue in our llms.txt that we were briefly convinced wasn’t our problem, but it was. The associated agent doc spec is also growing, turning ad-hoc conventions into something documented. The tools are new, the category is new, and everyone is figuring it out together.
On our list:
- Focus on accuracy. Continue testing whether an agent can complete tasks using a given doc page, similar to agent skills testing. Goal: fewer mistake-then-fix cycles.
- Offer interfaces built for agents. Like search APIs, and ways for them to send feedback when we get something wrong. Markdown is a human format agents happen to parse well, and we can do better than that.
- Think more about agent skills. There’s something wrong with committing
.claudefolders into every repo. Treating them likedevDependenciesfeels saner, and we’re watching how this evolves. - Continue integrating tools like
afdocs. Discuss with maintainers and submit PRs to include more (optional) checks, such as 404 handling and headers. - But most importantly, what every doc site has tried to do since the dawn of time: write good, reliable content. Treat docs like code, like tests, like the source of truth.
None of this is magic. Just small, honest work that only matters if the content is worth reading.
Thanks
Thanks to Neon and Databricks for letting engineers experiment (and for the tokens), and to my docs-team colleagues Dan and Barry for keeping the real docs moving while I poked at this.


